Тёмная сторона ИИ: GPT-4 нарушает авторские права
Компания Patronus AI, специализирующаяся на автоматизированном поиске ошибок в работе ИИ, провела исследование, чтобы найти плагиат в популярных языковых моделях. Результат тестирования удивляет: GPT-4 нарушает авторские права чаще других LLM!
Для поиска "пиратства" была разработана система CopyrightCatcher, позволяющая выявить образцы заимствованного контента. Она реагирует на появление в ответах материалов из различных источников (например, книг с платформы Goodreads) и отмечает случаи точного воспроизведения контента в выходных данных нейросетей.
Чтобы оценка была честной, разработчики выбрали случайные книги, попадающие под защиту авторского права, выделили 100-символьные образцы текста, с которыми будут сравниваться ответы нейросетей, затем создали подсказки, стимулирующие языковые модели выполнить поставленные задачи. 50 из них предлагали LLM продолжить отрывок из начала книги, ещё 50 — завершить текст на основе приведённого образца из конца произведения.
Тестирование проводилось среди четырёх нейросетей: GPT-4 от OpenAI, Claude-2.1 от Anthropic, Mixtral-8x7B-Instruct-v0.1 от Mistral и Llama 2 70B от Meta. Параметры эксперимента были одинаковыми для всех моделей: температура 0,1, максимальное количество новых токенов - 512, чтобы языковые модели не останавливались на середине предложения, не вносили "творческих искажений" и не превышали ограничения по длине вывода.
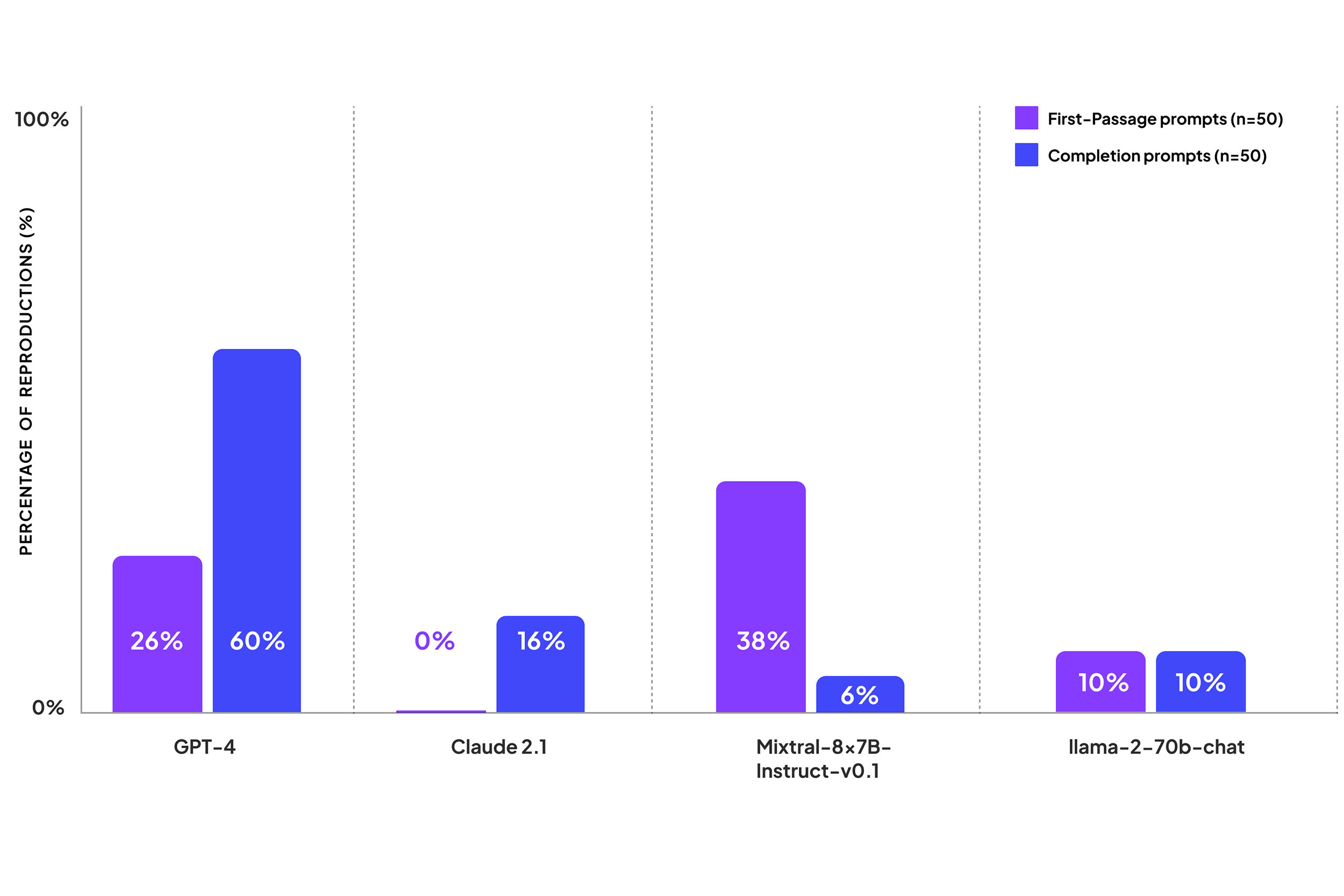
Худший результат у GPT-4. Языковая модель в 60% случаев завершала отрывок из конца книги, а в 26% случаев — дословно приводила образец из начала произведения!
Модель ни разу не указала на потенциальные нарушения авторских прав во время тестирования. Точный текст из книг демонстрировался в 43% случаев, однако, в 32% из них генерация обрывалась после нескольких слов. При этом LLM спокойно выполняла задачи на завершение контента из финальных глав произведений, дословно воспроизводя строки из книг, сборников стихов и поэм.
Mixtral также не очень безопасен: результаты языковой модели находятся примерно посередине между Claude 2.1 и GPT-4. Языковая модель в 38% случаев завершала первый отрывок книг, но редко предоставляла крупные фрагменты «пиратского контента» (всего в 6% случаев) или заполняла отрывки из конца произведения.
Claude 2.1 было сложнее "уломать" завершить предложение. Нейросеть настойчиво отвечала исследователям, что она не может закончить абзац, так как упоминаемое произведение защищено авторским правом. Ни одна из попыток продолжить текст из начала произведения так и не возымела успеха!
Однако LLM заканчивала текст из конца книги в 16% случаев, поэтому «антипиратская защита» Anthropic всё ещё не идеальна.
Llama 2 показала умеренные результаты. Без плагиата не обошлось, но его значение одинаково как для образцов из начала книг, так и из конца произведений, — везде по 10%.
Результаты исследования оставляют двойственные впечатления.
С одной стороны, разработчики LLM могли с самого начала заложить в свои продукты защиту от потенциального нарушения авторских прав, как это сделали в Claude 2, либо добавить фильтры «самоцензуры», подобные встроенным в Llama 2.
С другой стороны, избыточная цензура может привести к «отупению» модели. Это хорошо заметно на примере GPT-4.
Чем жёстче в OpenAI закручивают гайки, тем ниже падает креативность текста в LLM. Нейросеть уже сейчас заметно хуже генерирует творческий контент, чем Claude 3 Opus, не говоря уже о локальных LLM, специализирующихся на создании историй (например, Fimbulvetr и Dreamgen Opus v1.2).
Впрочем, проблемы заключаются не только в фильтрации, но и в используемых датасетах.
Даже если выкинуть из выборки лицензионный контент, в информации с форумов и публикациях с открытой лицензией могут встречаться цитаты из книг, фразы из популярных фильмов, пересказ событий или видоизменённые диалоги, строящиеся на основе других произведений. Это можно назвать "загрязнением", которое может привести не только к потенциальному нарушению авторских прав, но и появлению паттернов, ухудшающих впечатления от создаваемых историй.
Например, вы наверняка замечали, как ChatGPT-3.5 пытается разбить фэнтези и приключения на главы, содержащие завязку, основной сюжет и концовку, при этом формируя их по похожему шаблону, от которого сложно отойти.
Поэтому можно понять, почему коммерческие проекты пытаются засунуть в модели как можно больше данных, не заботясь об авторском праве. Однако это не оправдывает вред, нанесённый сообществу разработчиков "этичных" LLM и датасетов!
На этом моменте хочу сделать лирическое отступление.
Patronus AI — компания, получающая выгоду от сложившейся ситуации. GPT-4 нарушает авторские права? Против OpenAI начинается расследование? Давайте опубликуем CopyrightCatcher, чтобы найти нарушения и заработать на этом деньги!
Когда разработчики играют на страхах рынка и стремятся нажиться на чужих проблемах, к любым исследованиям стоит относиться с долей скепсиса. Подождать, пока появятся новые команды, метрики, системы анализа, а потом уже делать выводы.

А ещё у многих нейронок есть доступ к сети.
Модель может не содержать в датасете "легальный контент", но брать информацию о нём из блогов, форумов, рецензий и отзывов. На мой взгляд, это куда более крупная проблема! Уже сейчас LLM могут делать выжимки из данных, полученных в поисковых системах. Появляются поисковые машины, формирующие короткие ответы с помощью нейросетей. Проекты, собирающие информацию со страниц авторов, прикрепляя к выходным данным ссылки на оригиналы.
Увеличивают ли они кликабельность? Во многих, очень многих случаях — нет! Помогают ли блогерам набирать аудиторию? Тоже нет! Но они выгодны бизнесу и — пока — практически незаметны в правовом поле.
Поисковые системы с встроенными языковыми моделями, как и модели с выходом в интернет (GPT-4, Perplexity AI, You.com, Gemini), куда опасней для авторов, поскольку затрагивают огромный пласт творчества, находящийся в "серой зоне". Труд обычных людей, создающих тексты ради удовольствия. Мастеров своего дела, ведущих маленькие блоги или отвечающих на вопросы пользователей. Гиков, технарей, начинающих писателей.
Эти решения полезны для других «обычных людей», которым надоело искать бриллианты в тысячах SEO-статей. И они действительно могут облегчить жизнь!
Но для других они подобны медленному яду, убивающему творчество и мотивацию. И я не знаю, что может изменить ситуацию. Потому что избыточная цензура может погубить весь потенциал нововведений, а отсутствие какой-либо регуляции — загнать авторов в подполье, либо на площадки, которые полностью закроются от индексации в поисковиках, использующих нейросети.

Впрочем, не буду сгущать краски. Всё, что написано в последних абзацах, может навредить лишь в самом худшем случае!
Прямо сейчас поиск в сети с помощью нейросетей недалеко ушёл от вольного пересказа фильма от лица выпившего друга, который то и дело переключает своё внимание на что-нибудь ещё. Как и речь пьяного, выводы могут быть противоречивыми, неточными, а советы - попросту не работать.
К тому же, далеко не всё можно сжать до пары строк. Не удастся так легко вычеркнуть авторский стиль, идеи, взаимоотношения между персонажами, крутые истории. Пока в людях не угас интерес к творчеству, пока живое общение не стало моветоном, ничего по-настоящему жуткого не случилось!
Добавлю ещё кое-что от себя.
Помните времена, когда ChatGPT-3.5 можно было заставить войти в роль поехавшего учёного? Писателя эротики? Злого хакера, дающего советы по написанию вирусов? Обойти любые этические ограничения?
Лично я — да.
А ещё помню постепенное появление «цензурных фильтров», блокирующих всё, что может нанести вред пользователю. Войну между системой и хитроумными юзерами, создающими сложные промпты для обхода ограничений. Появление новых костылей, препятствующих генерации, чат-ботов, восстанавливающих «нецензурный» потенциал GPT. И так по кругу.
Сейчас генерировать что-то «запрещённое» в GPT-4 намного сложнее, чем несколько месяцев назад. Через год большая часть старых методов обхода перестанет работать. На их месте точно появится что-то новое, либо энтузиасты окончательно перейдут на улучшение локальных моделей, работающих на ПК, ноутбуках и смартфонах.
Но речь не об этом.
Точно таким же образом, как появилась цензура в LLM, появятся фильтры "авторских прав". Это лишь дело времени.
Ничто не мешает крупным игрокам (вроде OpenAI) интегрировать системы анализа датасетов, добавить поиск пиратского контента для удаления всего лишнего из языковых моделей (вплоть до покупки CopyrightCatcher или создания полноценного аналога), ввести регулярную проверку результатов генерации и дополнительный запрет на выдачу авторских материалов.
А пока этого не произошло, остаётся ждать двух вещей — завершения истории с регуляторами и появления сбалансированных языковых моделей, которые реально, а не топорно облегчат работу писателей, копирайтеров, маркетологов или разработчиков, но при этом не будут ущемлять права остального человечества.
Спасибо, что были со мной и дочитали этот пост до конца!
Обнимаю вас и желаю удачи~
Понравилась статья?
Поддержите автора репостом, донатом, подпиской на Telegram и другие страницы!
Tengyart
Профессиональный фотограф из Приморского края. Работаю в Находке, Владивостоке и Золотой Долине. Пишу статьи о фото и гик-культуре, в том числе про аниме, игры, путешествия и генеративные нейросети. Фотографии выкладываю на рабочей странице (https://olegmorozfoto.ru/) и в Telegram (https://t.me/tengy_photos). Всегда рад новым читателям, подписчикам и клиентам! ✨❤️


Читать ещё:

Microsoft убирает поддержку Windows Phone 8.1 и Windows 10 Mobile
Что появилось в обновлении Rank Math v1.0.45?
