Вышли открытые LLM модели Google — Gemma 2B и 7B
Компания выпустила две языковые модели с открытым доступом — Gemma 2B и Gemma 7B, созданные после долгих исследований, ранее породивших их «старшего брата» — Gemini. LLM модели Google позиционируются как легковесные и быстрые решения для разработчиков, подходящие для генерации безопасного контента на ПК, ноутбуках и в облачных сервисах.
Где скачать LLM модели от Google?
- Из репозитория Google на Hugging Face;
- В базе моделей LM Studio (доступна после установки программы);
- В результатах выдачи полнотекстового поиска по запросу «Gemma GGUF» (вариант, подходящий для доступа к новым квантованным версиям моделей);
- По прямой ссылке — 7B, 2B.
Как запустить Gemma 7B онлайн?
Самый простой способ запустить Gemma 7B онлайн и оценить возможности нейросети самостоятельно — перейти на HuggingChat, зарегистрироваться на сайте, либо открыть страницу в режиме гостя, затем перейти в настройки чата (запускаются по щелчку на иконку с шестерёнкой) и выбрать в меню google/gemma-7b-it.

После этого введите запрос в строке с надписью Ask anything и нажмите Enter. Через некоторое время появится ответ. Его можно модифицировать, удалить, сгенерировать заново, а также оценить результат с помощью лайка или дизлайка.

Дополнительная опция, которую можно использовать с онлайн-версией Gemma 7B — поиск в сети. Для её активации на HuggingChat нужно передвинуть ползунок с надписью Search Web вправо, для отключения поиска в сети — сдвинуть ползунок влево.
Что лучше — Gemma 7B или Gemma 2B?
В синтетических тестах (по результатам Open LLM Leaderboard) Gemma 7B в среднем обгоняет Gemma 2B на 17%. Поэтому можно сделать заключение, что в большинстве случаев модель 7B лучше, чем 2B. Однако иногда стоит обращать внимание и на маленькую версию нейросети от Google!
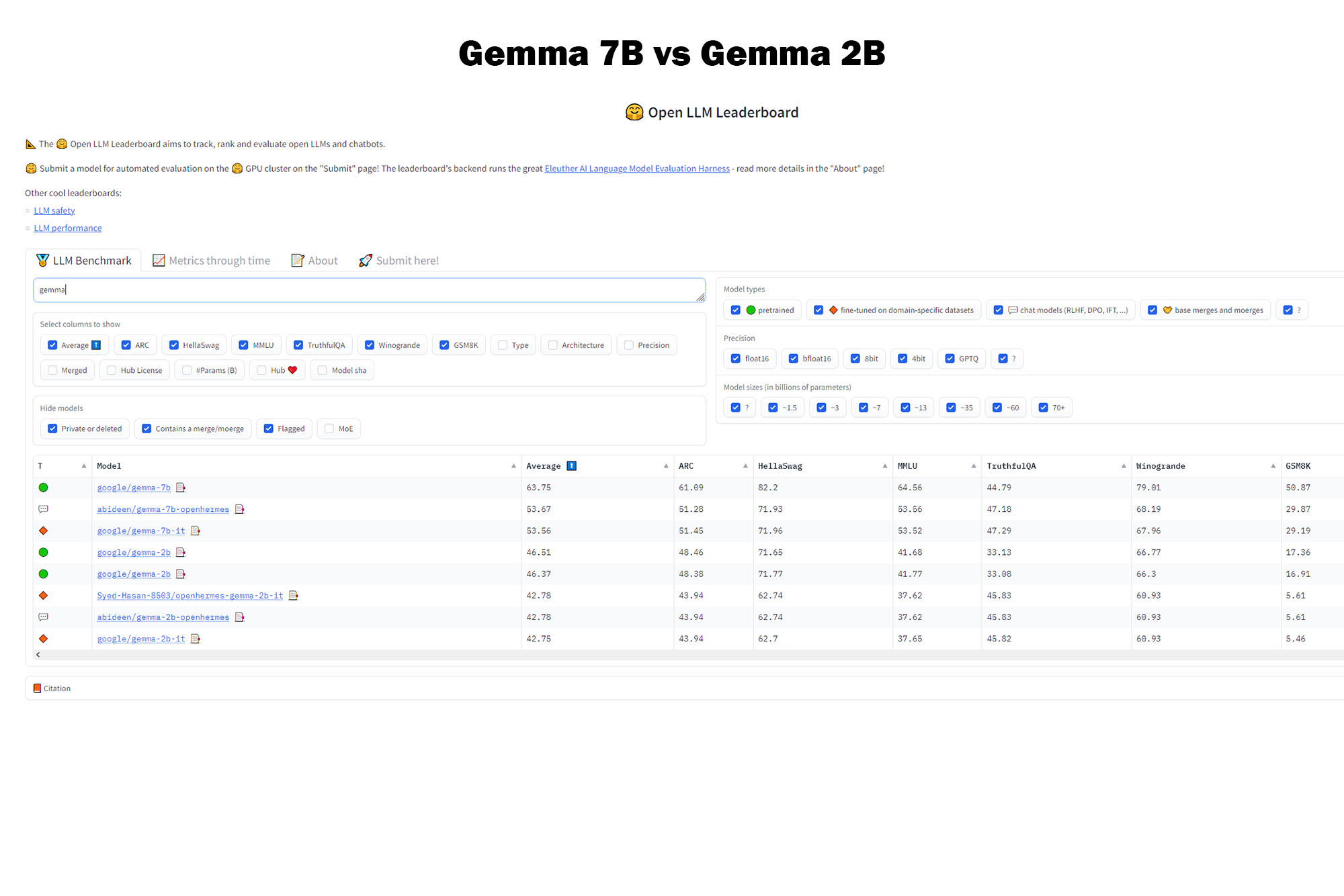
Во-первых, она почти не уступает старшей модели, когда дело касается обобщения текста, создания коротких описаний или генерации рекламных постов для социальных сетей. Полагаю, 2B LLM подойдёт для всего, что не требует особых знаний, выверенного слога и литературного мастерства.
Во-вторых, 2B модель почти в 2,5 раза быстрее, чем Gemma 7B, а также требует меньшего количества ресурсов для запуска и стабильной работы. Именно поэтому 2B - лучший выбор для слабых ноутбуков и ПК, несмотря на заметные потери в различных областях (кроме задач по математике и сложных лингвистических работ, т.к. там 2B слишком сильно проседает по качеству).
В-третьих, квантованная версия Gemma 2B реже галлюцинирует при генерации ответов на русском. 7B чаще сбивается на английский или смешивает слова на разных языках, усложняя читаемость текста. С другой стороны, у 2B модели заметно проседает согласованность предложений, так что «преимущество» не так уж велико.


Стоит ли использовать открытые LLM модели Google?
На мой взгляд, нет. Даже по результатам синтетических бенчмарков модели из серии Gemma уступают многим LLM аналогичного размера. Однако главные проблемы заключаются вовсе не в результатах тестирования, а в беспощадной цензуре и низком качестве генерации!
Я использовал обе модели, чтобы проверить их на креативность, знание истории, решение математических задач, а также для создания различных абстрактных публикаций - обзоров старых камер, статей про плагины, работу в Adobe Photoshop и даже ролевых игр, но... Испытал сильное разочарование.
Минусы Gemma 7B и Gemma 2B
Первое, что меня разочаровало — их быстродействие.
Несмотря на заявленную скорость работы этих LLM, нейросети на базе Mistral генерируют текст на 30-35% быстрее. Хотя данная проблема может быть исправлена в будущем (Mistral тоже не сразу начал быстро запускаться), модели из серии Gemma не ощущаются настолько производительными, как заявлялось в релизе Google.
Вторая причина для разочарования — цензура.
Цензура в нейросетях Google — тотальная и беспощадная. Даже там, где LLaMa выдавала результат, Gemma отказывается отвечать пользователю. Хотя чёрт с ними, с ролевыми играми! LLM может взбрыкнуть при любом намёке на «запрещённый контент», даже если вы спросите что-то в духе: «Как подготовить модель к ню фотосессии?».


Цензура может активироваться даже в абсурдных случаях, что откровенно раздражает. Модель не будет разговаривать на любые темы, которые посчитает небезопасными или потенциально вредными. Причём их "вредоносность" оценивается как попало, поэтому зачастую проще сразу переключиться на другую LLM, чем пытаться что-то выжать из языковых моделей от Google.
Впрочем, 7B чуть реже блокирует запросы, чем 2B, так что не всё потеряно.
Третья причина для разочарования — ограничения датасета.
Уж не знаю, на чём тренировали модели Gemma, но они очень плохо генерируют творческий и технический контент. И если с первым я не был удивлён (всё же упор на «безопасность» явно не идёт на пользу креативности), то плохое знание истории, техники и софта откровенно удивляет. Особенно на фоне того, что я получал хотя бы 50-60% правдивой информации от Mistral, OpenHermes, Supermario, Kunoichi и LLaMa, но в нейросетях от Google полезной информации в лучшем случае было 15-25% от всего текста.
Можно смириться со скупостью слога, дождаться, когда для Gemma появится что-то вроде собственной версии ChatML, создать агентов под разные задачи, но это не поможет получить результат там, где его нет.
Как исправить недостатки моделей прямо сейчас?
Во-первых, используйте Hugging Face Chat. Там есть лишь одна модель Gemma - 7B, но её ответы выглядят лучше, чем всё, что мне удалось сгенерировать локально. Кроме того, с помощью HF модель можно подключить к сети, исправив большую часть тех минусов, о которых я упоминал ранее.
Похоже, Gemma без квантования (используемая в чате на HF?) лучше справляется с задачами и в целом генерирует достаточно качественный текст, сравнимый с Mistral. Учитывая отвратительные результаты при использовании квантованных моделей в формате GGUF, возникает вопрос: «Это проблема локальных моделей, баги софта или результат обучения чата на запросах пользователей?».
Во-вторых, попробуйте изменить настройки программы, которую вы используете для запуска моделей. Особое внимание стоит уделить параметрам Output randomness, Repeat penalty и Top K Sampling.
Похоже, модели Gemma «не любят» как излишнюю креативность, так и штрафы за повтор. Например, после полного сброса Repeat penalty до 1 в LM Studio я стал реже получать бредовые ответы, чем при RP 1.18-1.27.
Могут ли в будущем пригодиться текстовые нейросети от Google?
Да. Хотя сейчас Gemma 2B и 7B показывают далеко не лучшие результаты, в будущем Google может выпустить новые версии текстовых нейросетей, либо заменить модели, исправив недочёты и дополнив датасеты новыми данными. А ещё не стоит забывать про огромное сообщество, ежедневно экспериментирующее с LLM!
Энтузиасты уже взламывали вшитую цензуру и тренировали нейронки, чтобы научить их новым навыкам, смешивали с другими моделями, чтобы повысить качество, либо обучали справляться с какой-то одной задачей (например, генерацией историй). Поэтому в будущем могут появиться альтернативные версии Gemma, которые вполне подойдут для экспериментов, творчества и работы.
Понравилась статья?
Поддержите автора репостом, донатом, подпиской на Telegram и другие страницы!
Tengyart
Профессиональный фотограф из Приморского края. Работаю в Находке, Владивостоке и Золотой Долине. Пишу статьи о фото и гик-культуре, в том числе про аниме, игры, путешествия и генеративные нейросети. Фотографии выкладываю на рабочей странице (https://olegmorozfoto.ru/) и в Telegram (https://t.me/tengy_photos). Всегда рад новым читателям, подписчикам и клиентам! ✨❤️



Один комментарий
Юрий
Спасибо! Хороший, конструктивный обзор, сэкономили время. Можете пдсказать, где можно детально познакомиться со студией LM?