Плюсы LM Studio для запуска LLM на Windows 10 (11)
Сталкивались с программами для запуска LLM, от которых горела задница? Искали, с чего начать, но боялись неповоротливых мастодонтов, требующих вводить git clone, выкачивать гигабайты данных, переустанавливать софт после выхода нового патча с фатальными багами?
Забудьте о них, как о страшном сне, лучше используйте LM Studio AI!
Что такое LM Studio?
LM Studio — легковесное кроссплатформенное приложение для экспериментов с локальными языковыми моделями (LLM), подходящее для Windows 10 (11), Mac (M1/M2/M3) и Linux.
Отличительные особенности - компактный размер, быстрый запуск, поддержка GPU Offload и расширенного контекстного окна, настройка длины контекста одним нажатием, пресеты конфигураций для различных типов моделей (от ChatML до Zephyr и Mistral), лаконичный графический интерфейс, база данных с популярными LLM, возможность скачать любую GGUF модель с Hugging Face по названию или ссылке с репозитория, отображение использования RAM и нагрузки на CPU, экспорт скриншотов чата в формате PNG.


По удобству использования программа больше всего похожа на гибрид GPT4ALL и Koboldcpp.
Как и GPT4ALL, идеально подходит для работы с чатом и реализации технических задач. Все действия выполняются в GUI (нет необходимости в браузере), интерфейс отличается простотой и практичностью — настройки отображаются справа, чат и меню — слева, всё лишнее в любой момент можно скрыть, свернув боковые панели. Koboldcpp напоминает по другим причинам — частоте выхода патчей, активной работе с сообществом, поддержке нестандартных подсказок (например, формата ChatML).
По творческому потенциалу уступает Koboldcpp и Text-generation-webui. В программах больше настроек для отыгрывания персонажей, создания приключенческих историй и имитации диалогов. Этот недостаток отчасти можно исправить, импортируя или вводя с нуля системные подсказки. Используя их, можно улучшить качество фанфиков, проапгрейдить RP и ERP. Однако с параметрами по умолчанию придётся долго перебирать доступные модели LLM, либо готовиться неоднократно редактировать текст.
Зато LM Studio отлично справляется с базовыми задачами — созданием технических отчётов, маркетинговых постов, редактированием черновиков, генерацией идей, шаблонов ответов и писем.
Другое преимущество программы перед конкурентами — отличное качество длинных публикаций. Нужно создать статью свыше 5000 символов? Легко! Продолжить диалог более двух-трёх раз и не сбиться? Вообще не вопрос, лишь бы модель поддерживала длину контекста, а системе хватало мощности!
Koboldcpp и GPT4ALL хуже справляются с лонгридами. Чаще возникают галлюцинации, повторы, потери данных. Не могу сказать, что в LM Studio происходит какая-то магия (глюки тоже случаются), но программа работает стабильней, поэтому проблем с ней меньше.
Дополнительные подробности о настройках ПО.
За длину контекста отвечает параметр Context Lenght, за ускорение генерации - GPU Offload. Если упрощать, первый отвечает за максимальное число токенов, которыми может оперировать LLM, последний - за количество слоёв модели, загруженных в память ГП. Чем больше слоёв выгружено, тем быстрее создаётся текст (с определёнными ограничениями), но возрастает нагрузка на систему, и наоборот.
Попробую на примерах показать, как длина контекста и выгрузка слоёв воздействуют на ОС.
Для запуска OpenHermes 2.5 Mistral 7B в GPT4ALL требуется 4-5 ГБ свободного места в RAM, плюс 4,3-4,5 ГБ общей памяти графического процессора. LM Studio с 27-31 слоями GPU Offload и длиной контекста 32K потребляет около 9 ГБ памяти и 8,7-8,9 ГБ общей памяти графического процессора.
Чтобы ослабить нагрузку на систему, достаточно уменьшить количество слоёв и ограничить длину контекста. При GPU Offload 0 и Context Lenght (n_ctx) 4096 нагрузка на память падает до 1,2-1,3 ГБ, а расход общей памяти ГП - до 0,9-1,0 ГБ.

Теперь попробую изменить настройки, чтобы показать на практике разницу в скорости создания контента.
Запустив OpenHermes 7B на RTX 2070 Super, установив Context Length на 4096 и отключив GPU Offload, я генерировал текст со скоростью 5-6 токенов в секунду. После выгрузки 31 слоя в ГП скорость генерации возросла до 42 токенов в секунду. Изменив размер контекстного окна до 32768, получил 36 токенов в секунду.


С небольшим размером контекстного окна (4096 токенов) можно выгрузить больше слоёв, чем рекомендуется в LM Studio. Например, 35-50 вместо 10-31.
Используя 39 слоёв с моделью OpenHermes 7B и RTX 2070 Super, я генерировал текст со скоростью 63-64 токенов в секунду. Уверен, на новых и куда более мощных видеокартах результат будет намного круче!
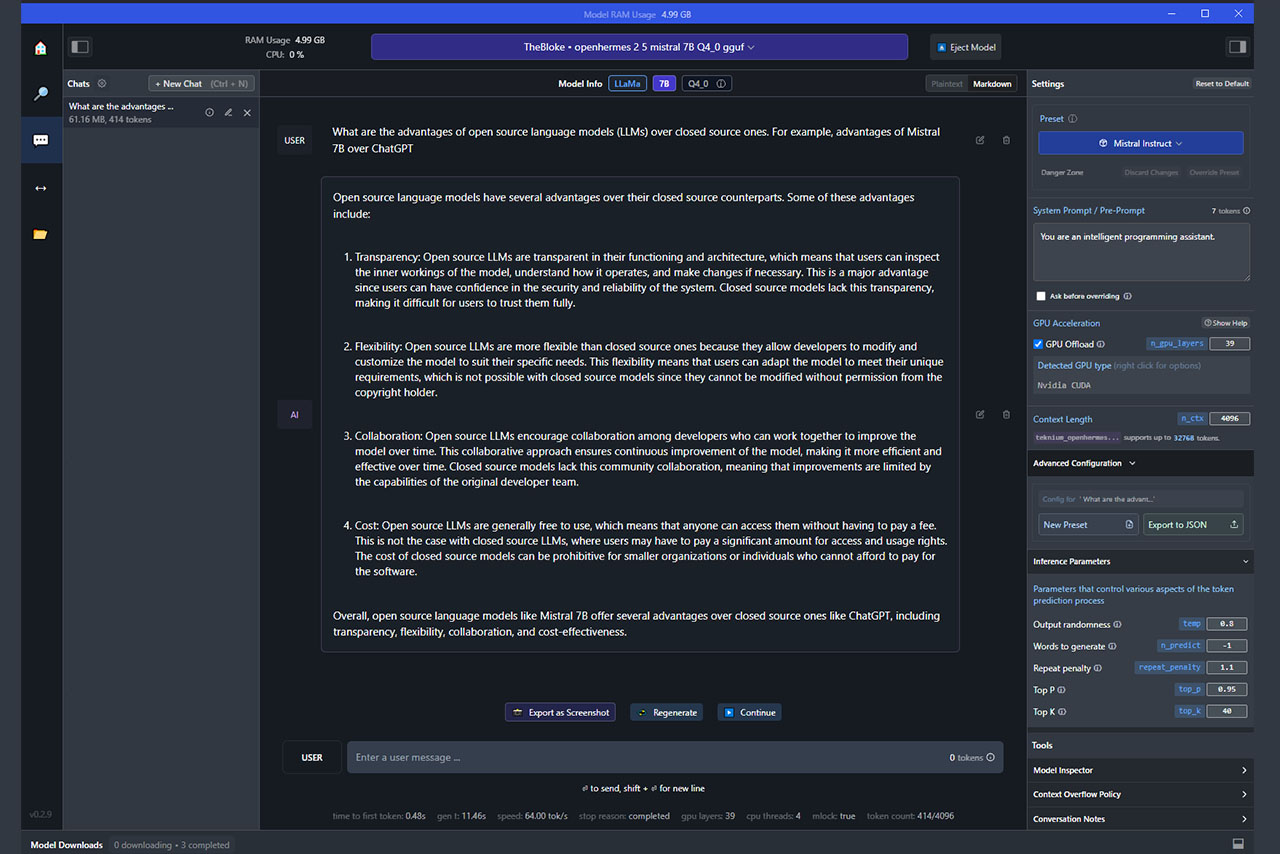
Однако при чрезмерной выгрузке слоёв наблюдается замедление генерации, падение производительности системы, зависание программы или частое появление глюков в текстах. Поэтому рекомендую подбирать оптимальные настройки в зависимости от размера контекстного окна (больше токенов — меньше слоёв в GPU Offload), веса модели (в 7B больше слоёв, в 33B — меньше), объёма видеопамяти и мощности видеокарты.
Помимо этого, советую ориентироваться на загруженность системы. Чтобы оценить нагрузку во время работы LM Studio, запустите диспетчер задач на Windows 10, откройте раздел «Производительность», затем перейдите в «Графический процессор». Постарайтесь не использовать настройки, потребляющие более 60-70% ресурсов выделенной, оперативной и общей памяти графического процессора.

Дополнительно обращайте внимание на потребление RAM. Если текстовая нейросеть превышает все доступные ресурсы оперативной памяти, даже разгрузка с помощью видеокарты делу не поможет, так что тормозить будет не только GUI, но и вся система! В подобном случае стоит выбрать другую модель, либо сделать апгрейд компьютера.
Если проблемы наблюдаются при соблюдении всех рекомендаций, попробуйте начать с выгрузки небольшого количества слоёв модели в GPU (5-10), затем постепенно увеличивайте или уменьшайте значение, пока не найдёте баланс между скоростью генерации и нагрузкой на ГП.
Удачных экспериментов!
Понравилась статья? Поддержите автора репостом, комментарием, подпиской на Telegram и другие страницы!


Читать ещё:

Как из-за General Motors разорились трамвайные компании?

Портрет Эндрю Джексона в нейросети Artbreeder
